Building a Comprehensive LangChain Application: A Step-by-Step Guide
Written on
Chapter 1: Introduction to LangChain Applications
In recent times, there has been a surge in the utilization of LangChain applications and large language models. After examining numerous implementations and creating a few myself, I felt compelled to share insights on the fundamental concepts and procedures involved in building an application powered by LLM and LangChain. My expertise primarily revolves around semantic search and question-answering, so variations may exist for other NLP tasks, though these are likely to be minor.
Step 1: Data Extraction
I will not delve into web scraping or the initial dataset acquisition, as these topics are vast. Instead, I'll assume you already possess a collection of text files containing the information or documents upon which your LLM application will be built.
Step 2: Initialization – Preparing Your Data
This phase typically requires only a one-time execution for a LangChain application. Upon completion, you will have a chain/model primed for inference, serving as the backend for your application.
- Loading the Data
LangChain provides an extensive range of document loaders. Here are some commonly used options:
- URL Loader / YouTube Transcripts: Enter a list of URLs, and the loader will fetch their content directly for your dataset. A PlaywrightURLLoader can also be utilized for various data formats, including videos.
- File Directory (txt files, markdown files, etc.) & PDFs
- Arxiv: A frequently pursued application is a question-answering system for lengthy scientific papers.
- Git: For question-answering over code.
- Google BigQuery: Create a query and use this loader to automatically import data from BigQuery, which is particularly beneficial for business analytics.
- Slack: Building a QA application using Slack data is an excellent idea, as it serves as a powerful knowledge base for many companies today.
- Simple Data Processing
No intricate NLP preprocessing is necessary; simply provide an appropriate chunk size, which may require some experimentation.
By implementing an effective chunking strategy, we can enhance the accuracy of search results to capture the essence of user queries. If the text chunks are either too small or too large, they may lead to imprecise results or overlook relevant content. A helpful guideline is that if a text chunk makes sense on its own, it will likely make sense to the language model too. Thus, determining the optimal chunk size for your document corpus is crucial for ensuring accurate and relevant search outcomes.

Source: Unsplash
- Embedding the Data
Without getting too technical, embeddings are numerical representations of words, enabling computers to process language. The primary challenge in NLP lies in transforming words into meaningful numerical values.
LangChain supports various text embedding models, commonly employed include:
- OpenAI Embeddings Model
- HuggingFace Hub
- Self-hosted options (for privacy purposes)
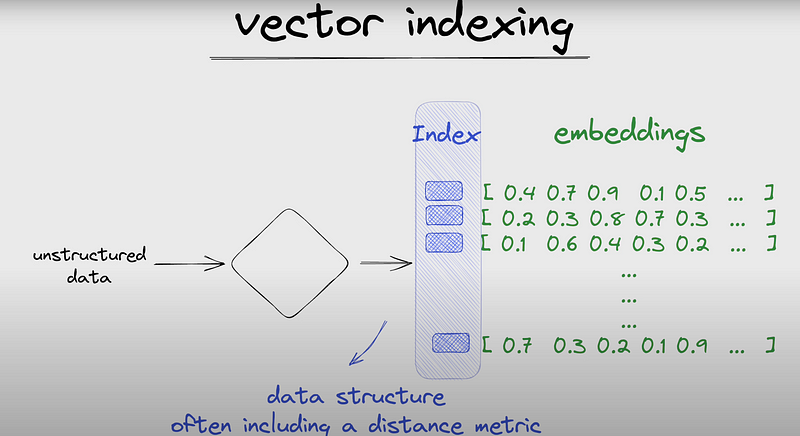
- Indexing the Embeddings
Embeddings exist as vectors—a list of numbers. The term Vectorstore or VectorDB refers to a database optimized for storing and querying these vectors. With the increased use of LLMs, vector stores have gained popularity, as discussed in this informative video by Fireship.
Vector databases employ indexes to streamline data retrieval. An index is a data structure that enhances the speed of data retrieval operations in a database, albeit at the cost of additional storage for maintaining the index. You can think of indexes similarly to an alphabetical index in a dictionary, which helps you quickly locate a word.

Source: Youtube
Various algorithms are available for identifying similarities between vectors/embeddings. The main goal of these algorithms is to determine the differences between vectors as accurately and numerically as possible. One straightforward method is calculating the algebraic dot product of vectors, which involves summing the corresponding entries of two equal-length vectors. Another approach is geometric, utilizing the magnitudes of the vectors and the cosine of the angle between them.
Different algorithms for indexing vectors include Product Quantization, Locality-Sensitive Hashing, and Hierarchical Navigable Small World, among others.
Step 3: Model Inference
Now that we have loaded the data and established an index (which typically only needs to be done once, unless online training is introduced), we can explore the inference pipeline. This pipeline executes each time a user submits a query to the LLM.
Source: Youtube
When a user submits a query via an HTTP request to the application’s server, the next step is to generate the embedding for that query. With the vector representing the user’s query, we merely need to retrieve the numerically closest vector from the dataset. Assuming our embeddings are accurate, the closer the numbers, the closer their linguistic meanings will be. Thus, the solution to the user’s inquiry should be found in the documents/embeddings with the smallest numerical difference.
To achieve this, we employ strategies to calculate the numerical vector difference (e.g., dot product, cosine similarity, etc.). Subsequently, we can utilize a simple algorithm known as K-Nearest Neighbors, which identifies the closest K vectors to the query vector.
At this juncture, we essentially have an answer to the query, but for optimal results, two enhancements can be made:
- Implement post-processing, such as re-ranking the K nearest neighbors using a more precise similarity measure.
- Send the K nearest neighbors to a robust model (like ChatGPT) to utilize a LangChain chain for text completion and summarization.
Final Thoughts
I hope this article has been insightful. I have spent time grappling with these concepts, and I believe this summary adequately captures the anatomy of LangChain applications. A powerful LLM application will optimize the following steps:
- Loading the cleanest data
- Applying the most effective chunking strategy
- Utilizing the best AI model for embedding
- Leveraging an optimized vector database
- Selecting the most suitable AI model and chain type for text completion and summarization
Discover the fundamentals of building applications with language models in this comprehensive LangChain crash course.
Join us for an in-depth tutorial on LangChain, covering essential concepts and practices for effective application development.