generate a novel search algorithm for AI: Policy-Guided Heuristic Search
Written on
Chapter 1: Introduction to Search Algorithms
In the realm of machine learning, most methods operate under the premise that both training and testing data originate from the same statistical distribution, known as IID (independent identically distributed). However, real-world scenarios often involve adversarial data that undermines this assumption, especially in competitive environments like Go and Chess.
Previous advancements, notably DeepMind’s AlphaGo and its successors, utilized the polynomial upper confidence trees (PUCT) algorithm, which has shown efficacy in guiding searches in adversarial contexts. Nevertheless, PUCT lacks assurances regarding its search efforts and often proves computationally demanding. While alternative approaches like LevinTS offer guarantees on search steps, they do not incorporate heuristic functions.
To overcome these limitations, a collaborative team from DeepMind and Alberta University has introduced a new approach termed Policy-Guided Heuristic Search (PHS). This innovative algorithm leverages both heuristic functions and policies while also ensuring guarantees on search loss that reflect the quality of both elements.

Section 1.1: The Limitations of PUCT
The PUCT algorithm aims to ensure that a model's value function converges to the actual value function over time. However, this guarantee fails when real rewards are substituted with estimated values, complicating the application of PUCT to challenging deterministic single-agent problems.
The more recent A* combined algorithm incorporates a learned heuristic function that balances solution quality with search time, typically outperforming PUCT. Yet, A* focuses on achieving minimum cost solutions, which diverges from the goal of minimizing search loss, such as the number of search steps.
On the other hand, Levin Tree Search (LevinTS) employs a learned policy to streamline its search process and reduce the number of search steps, factoring in the quality of the policy but lacking the capability to learn heuristic functions.
Chapter 2: Introducing Policy-Guided Heuristic Search
The PHS algorithm merges the policy-guided search of LevinTS with the heuristic-based search of A*, resulting in a novel methodology. Designed to tackle unknown tasks efficiently—starting with minimal knowledge—PHS aims to resolve them as swiftly as possible. Unlike traditional algorithms that focus on minimizing path loss solutions, PHS aims to minimize overall search loss without the requirement for path-cost optimality.

Section 2.1: Enhancements of PHS
PHS expands upon LevinTS by accommodating arbitrary nonnegative loss values instead of strictly setting loss to one, incorporating a heuristic factor that is at least one. The researchers demonstrate that for any nonnegative loss function, policy, and heuristic factor, PHS will yield a solution node. Additionally, they establish that PHS has an upper bound on search loss, and that an effective heuristic can significantly lessen the number of search steps taken.
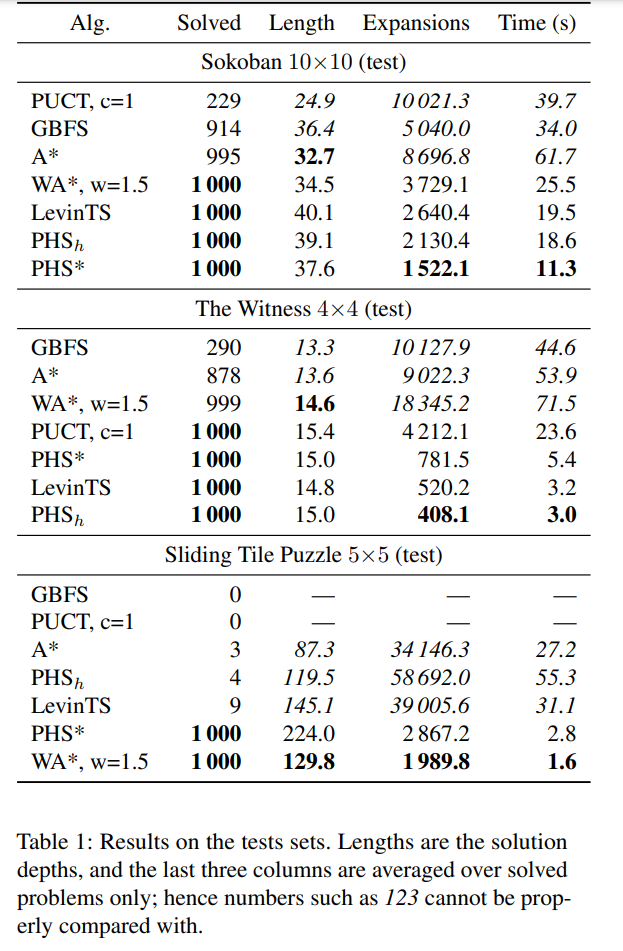
The research team compared PHS against various policy-guided and heuristic search algorithms, including PUCT, LevinTS, A*, Weighted A* (WA*), and Greedy Best-First Search (GBFS). Their evaluation encompassed challenges like the 5×5 sliding-tile puzzle, Sokoban (Boxoban), and a puzzle from the video game The Witness.

Section 2.2: Performance Evaluation
The PHSh and PHS* algorithms excelled in the Sokoban domain, while in The Witness, the policy-guided BFS-based algorithms (PUCT, PHS*, LevinTS, and PHSh) performed the best. Notably, GBFS struggled in this scenario due to its reliance solely on heuristic quality. In contrast, WA* and PHS* effectively solved the Sliding Tile Puzzle challenges, clearly surpassing other algorithms.
Overall, the findings indicate that PHS facilitates rapid learning of both policy and heuristic functions, exhibiting strong performance across all three testing domains concerning the number of problems resolved and the time taken for searches.
The first video discusses the need for a cautious yet optimistic approach towards AI, featuring insights from the CEO of Google DeepMind on the future of artificial intelligence.
The second video explores the advancements in AI products, highlighting Deeni's journey within Google DeepMind and the innovations being developed.

Stay informed about the latest developments and breakthroughs in AI by subscribing to our popular newsletter, Synced Global AI Weekly.